The torchvision.models subpackage contains definitions of models for addressing different tasks, including: image classification, pixelwise semantic segmentation, object detection, instance segmentation, person keypoint detection, video classification, and optical flow.
For the CLASSIFICATION TASKS, the following classification models are available, with or without pre-trained weights:
Convolution Neural Network - CNN
EfficientNetV2 - EfficientNetV2: Smaller Models and Faster Training - 2021
TorchVision Model EfficientNetV2 for Image Classification pic.twitter.com/gxVJs82gYS
— PyTorch Sequences (@HoangDo51647820) October 28, 2022
Authors: Mingxing Tan, Quoc V. Le.
Architecture
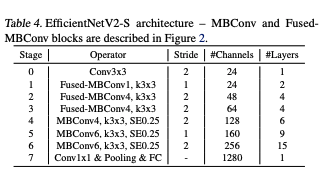
The maximum inference image size to 480.
Model accuracy, inference time and maximum frame rate
- EfficientNetV2-S - 83.9% - 24ms infer time - 42 fps max
- EfficientNetV2-M 85.1% - 57ms infer time - 17 fps max
- EfficientNetV2-L 85.7% - 98ms infer time - 10 fps max
MobilenetV3 - Searching for MobileNetV3 - 2019
Authors: Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam
pretrained torchvision.models MobileNetv2 inference pic.twitter.com/sw4OPiJv0d
— PyTorch Sequences (@HoangDo51647820) October 31, 2022
Other CNNs
-
ConvNeXt - A ConvNet for the 2020s - 2020 Authors: Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie
-
EfficientNet - EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks - 2019 Authors: Mingxing Tan, Quoc V. Le
-
RegNet - Designing Network Design Spaces - 2020 Authors: Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár
-
MNASNet - MnasNet: Platform-Aware Neural Architecture Search for Mobile - 2018 Authors - Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le
-
MobileNet V2 - MobileNetV2: Inverted Residuals and Linear Bottlenecks - 2018 Authors: Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
-
ShuffleNet V2 - ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design - 2018 Authors: Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun
-
ResNeXt - Aggregated Residual Transformations for Deep Neural Networks - 2017 Authors: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
-
DenseNet - Densely Connected Convolutional Networks - 2016 Authors: Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger
-
ResNet - Deep Residual Learning for Image Recognition - 2015 Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
-
Inception V3 - Rethinking the Inception Architecture for Computer Vision - 2015 Authors: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna
-
GoogLeNet - Going Deeper with Convolutions - 2014 Authors: Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich
-
AlexNet - ImageNet Classification with Deep Convolutional Neural Networks - 2012 Authors: Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
-
SqueezeNet - SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size - 2016 Authors: Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, Kurt Keutzer
-
Wide ResNet - Wide Residual Networks - 2016 Authors: Sergey Zagoruyko, Nikos Komodakis
-
VGG - Very Deep Convolutional Networks for Large-Scale Image Recognition - 2015 Authors: Karen Simonyan, Andrew Zisserman
ViT - Vision Trarnsformer
-
SwinTransformer - Swin Transformer: Hierarchical Vision Transformer using Shifted Windows - 2021 Authors: Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo
-
VisionTransformer - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale - 2020 Authors: Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby


